
LSI-фразы: что это такое и как их собрать

Алексей Солдат Редактор Texterra
Я делюсь самым эффективным алгоритмом поиска LSI-фраз, который я постоянно использую в своей работе. В результате за полчаса вы научитесь рассчитывать необходимое количество LSI-фраз и находить нужные.
Что такое LSI-копирайтинг
«Пишите для народа». — говорят они. Как поисковая система узнает, что контент на моем сайте удовлетворяет желания пользователей? LSI-копирайтинг решает эту задачу.
Если пользователь набирает в поисковой системе фразу «консультация гинеколога», он, по крайней мере, хочет увидеть информацию о ценах, задать уточняющие вопросы и заполнить форму записи на прием. То есть фразы «гинеколог спросить», «гинеколог цены», «запись к гинекологу» и «гинеколог онлайн» являются синонимами запроса.
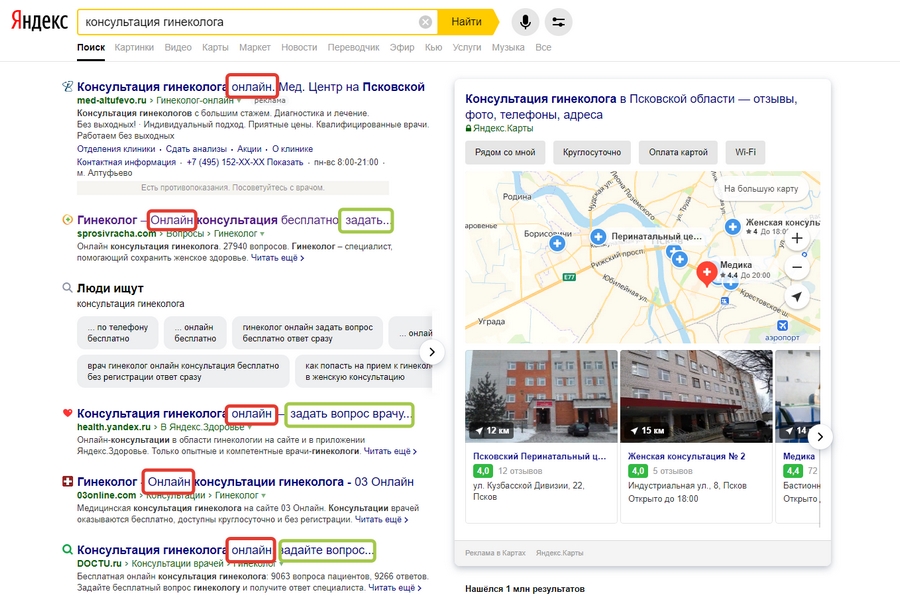
Поисковая система выясняет, на каких страницах пользователи проводят больше времени, и составляет список LSI-фраз на основе содержания этих страниц. При поиске он использует не только конкретный запрос, но и LSI-фразы.
Поисковая система классифицирует страницу как коммерческую или информационную, основываясь на LSI.
Сложно продвигать коммерческую страницу, если ее текстовое содержание изобилует фразами, характерными для информационного запроса, и наоборот. То есть LSI важен для правильной классификации сайта.
Ранжирование документов с LSI-оптимизацией и без
Связь рассчитывается между внутренними страницами и внешними документами. Он похож на перелинковку и получение ссылок с других доменов, но состоит только из слов. Чем сильнее ссылка, тем выше ранжируется страница. В патенте Google (ранжирование документов с помощью слов-связок) это прямо указано. Чем обширнее LSI-семантика в документе и на всей странице, тем легче продвигать страницы.
Без LSI в конкурентных областях делать нечего: поисковая система воспримет содержимое страницы как недостаточно качественное, то есть не удовлетворяющее запросам.
Откуда взять LSI-семантику
Проблема 1: Как придумать синонимы и родственные фразы? Можно использовать мозговой штурм и сбор поисковых терминов. В этом случае возникает другая проблема.
Проблема 2: Как выяснить, какие LSI-фразы из полученного массива наиболее релевантны для поисковика?
Существует простой способ решения обеих проблем.
Шаг 1. Сбор маркерных запросов
Маркерные запросы являются основой семантического ядра. Например, для коммерческого сайта, продающего кирпичи — «купить кирпичи», «кирпичи с доставкой» и т.д.
Частота ядра — это то, сколько раз фраза «купить кирпичи» встречается во всех возможных вариациях: «купить силикатный и известковый кирпич», «купить дешевый красный кирпич» и т.д.).
Точная частота — это количество конкретных запросов «купить кирпичи» без расширения.
Чем больше разница между базовой и точной частотой, тем больше фраз можно создать из маркерного запроса путем добавления других LSI-слов и фраз.
Маркерные запросы характеризуются большой численной разницей между базовой частотой и точным вхождением фразы. Поэтому мы специально ищем маркерные запросы по данному кластеру (семантической группе) для 1 целевой страницы.
Что такое LSI и как получить LSI-фразы, анализируя спрос #4.1
Сгенерируйте и расставьте по страницам семантическое ядро для продолжения. Соберись пока. Я пошел разливать чай — вода уже закипела.
Шаг 2. Поиск конкурентов для изъятия LSI-фраз
Откройте инструмент Arsenkin Tools, найдите инструмент «Получить 10 лучших сайтов». Там введите все маркерные запросы для одной страницы, задайте регион (делайте это всегда, даже если страница не имеет географической привязки) и нажмите «Начать проверку».
В качестве альтернативы Арсенкину можно использовать Key Collector, PR-CY, Serpstat, Pixeltools, Topvisor.
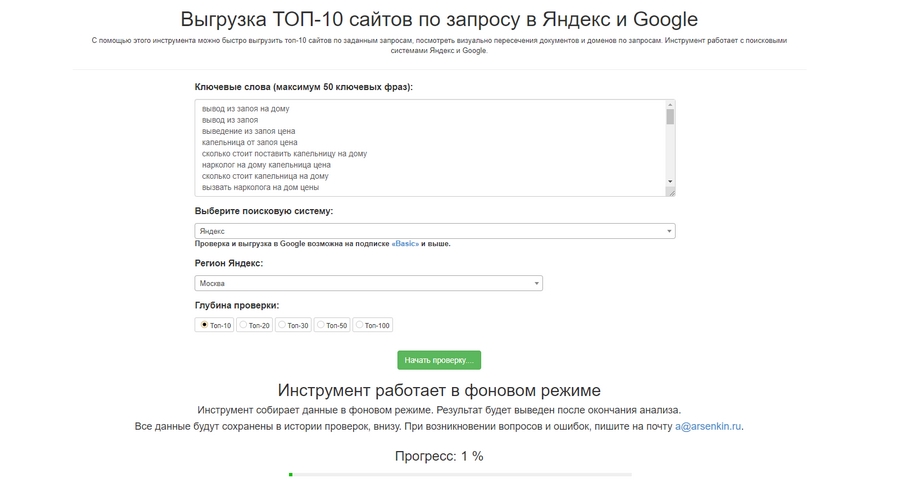
Из введенного списка мы получили столбец для каждого запроса. В каждой колонке — 10 страниц из топа Яндекса по данному запросу. Разумеется, в колонках нет рекламы. Колонки разноцветные: одинаковые URL-адреса, разбросанные по разным колонкам, выделяются одним и тем же цветом:

Наша задача — прокрутить вниз до этого блока:
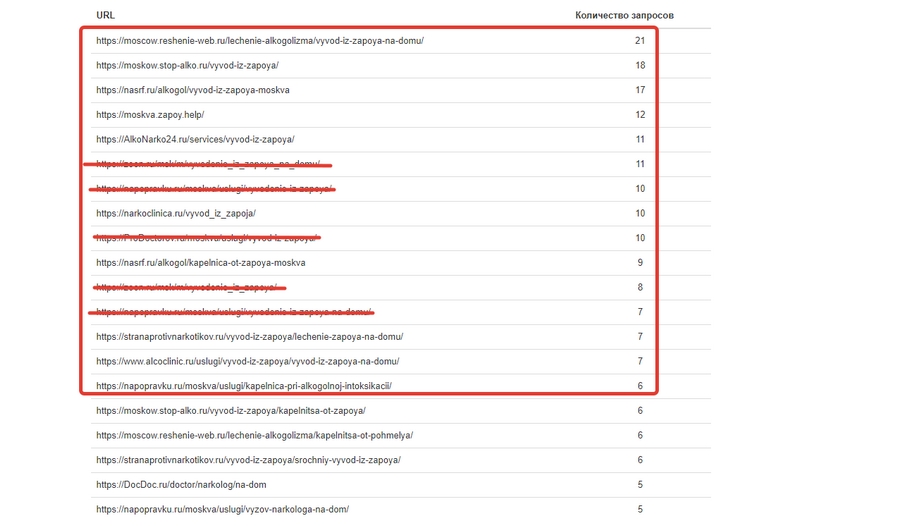
Как вы видите, я уже удалил агрегаторы и выделил первые 10 релевантных ссылок. Эти страницы чаще всего появляются в результатах выгрузки, то есть они занимают первое место по большему числу запросов, чем остальные. Мы обнаружили, что маркерные запросы на этих страницах широко ранжируются, включают много LSI, и страницы имеют хорошие поведенческие факторы.
Шаг 3. Таблица для исследования и веб-анализа LSI-семантики конкурентов
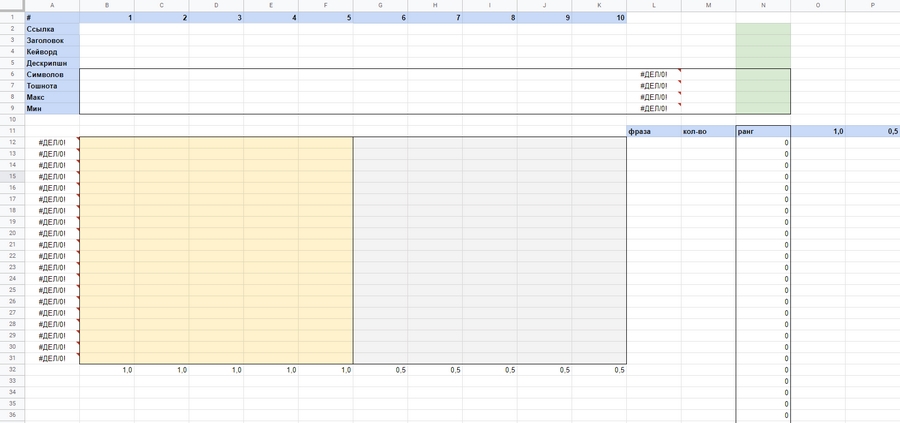
У меня было два варианта — подсчитать все вручную для каждой страницы или применить формулы и сохранить шаблон для использования в случае необходимости. Я создал шаблон настолько, насколько позволяли мои навыки работы с Excel. Я известный специалист по Excel. Это выглядит следующим образом:
Чем лучше всего собирать LSI фразы?
Рассмотрим верхний блок и содержащиеся в нем строки: количество символов, тошнота, максимальная тошнота и минимальная тошнота. Мы рассчитаем эти значения для каждой из 10 страниц, а в таблице вычислим среднее арифметическое. Таким образом, мы сможем увидеть тенденции в зависимости от того, какие страницы находятся на вершине. Например, объем текста или плотность ключевых фраз.
Ниже показаны две коробки, одна бежевая, другая серая. Колонка формул слева от этих ячеек показывает переход от среднего максимума к среднему минимуму скуки, умноженный на 100 для простоты расчета.
Желтая рамка будет содержать пять верхних сторон, а серая — пять нижних. Разница между первой и второй пятеркой заключается в их рейтинге. Первые пять имеют кратный верхнему вес.
Все числовые значения, которые мы получим в процессе, будут умножены на коэффициент. Для желтого поля это будет 1, а для серого поля — 0,5.
В нижней правой части листа 1 приведены результаты нашей выборки, где каждому слову присвоен ранг. Чем выше ранг, тем ближе должна быть максимальная плотность вхождений этого слова в содержимое документа. Чем ниже ранг, тем ближе к минимуму, но все еще в пределах диапазона не ниже минимума.
Шаг 4. Парсинг LSI-фраз и обработка результатов
Теперь зайдите на сервис SeoLik (или его p2pi-аналог) и найдите инструмент «Анализ контента»:
Возьмите первую из десяти ссылок и вставьте ее в поле анализа содержания. В результатах найдите поля с изображений ниже и введите значения из них в таблицу в соответствующие ячейки:

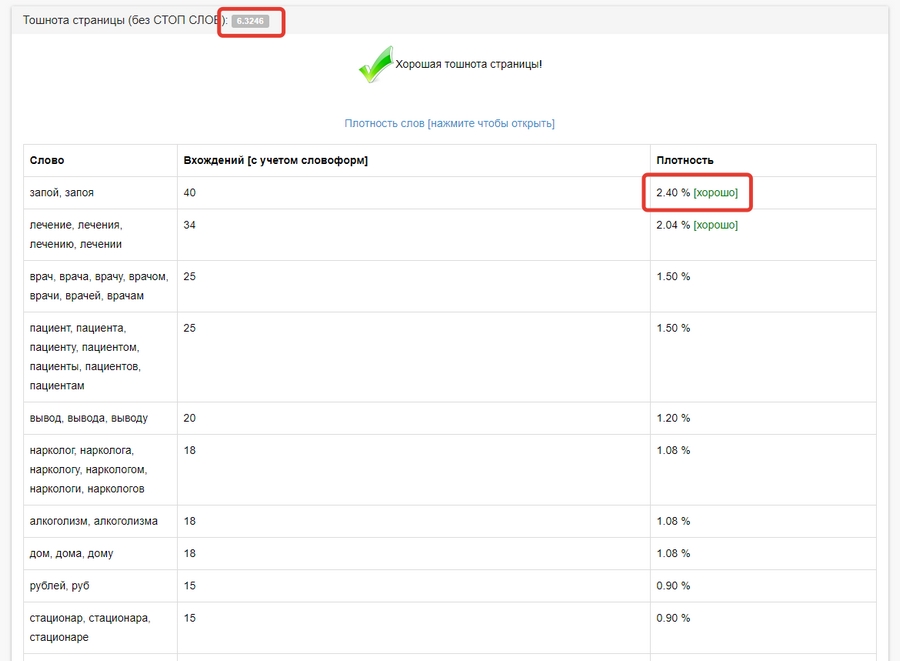
На втором изображении мы видим список слов. Введите первые 20 в желтый столбец таблицы. Минимальным значением тошноты для этой страницы будет значение тошноты 20. слов: «запой», «лечение», «врач», «пациент» и т.д.
Повторите ту же процедуру с оставшимися девятью страницами, постепенно заполняя желтые и серые поля:
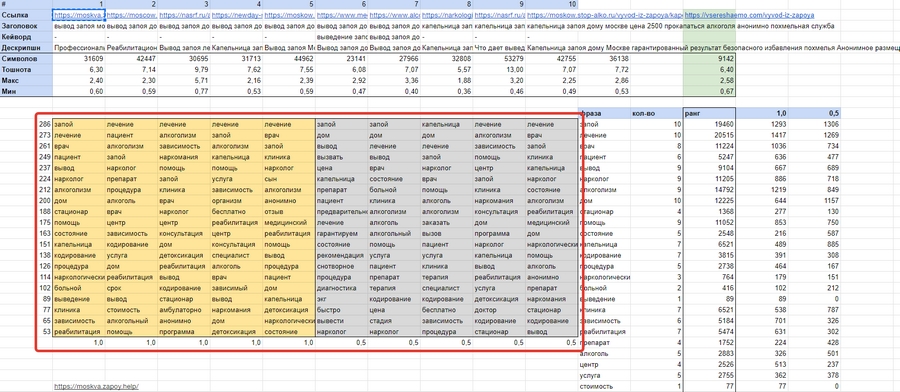
Теперь остановитесь у желтой коробки.
Нужно найти одинаковые фразы в каждом из пяти столбцов, умножить каждую на соответствующее число в столбце слева от желтого квадрата. Подсчитайте сумму значений, запишите слово и результат в соответствующие клетки справа. Введите количество совпадений в колонке ‘Number’.
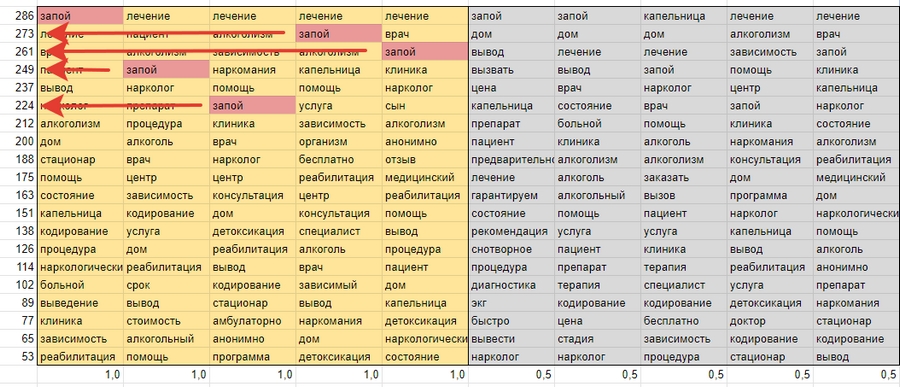
Проделайте ту же процедуру отдельно с серой рамкой, но внесите результаты расчета в колонку с коэффициентом 0,5:
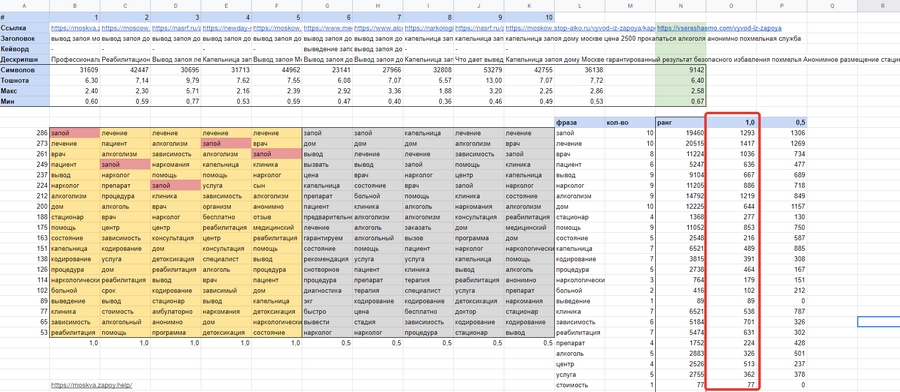
Скопируйте столбцы «Фраза», «Номер» и «Ранг». Создайте новый лист в документе, щелкнув правой кнопкой мыши ячейку B2 и выбрав команду Paste Special > Paste Value Only:
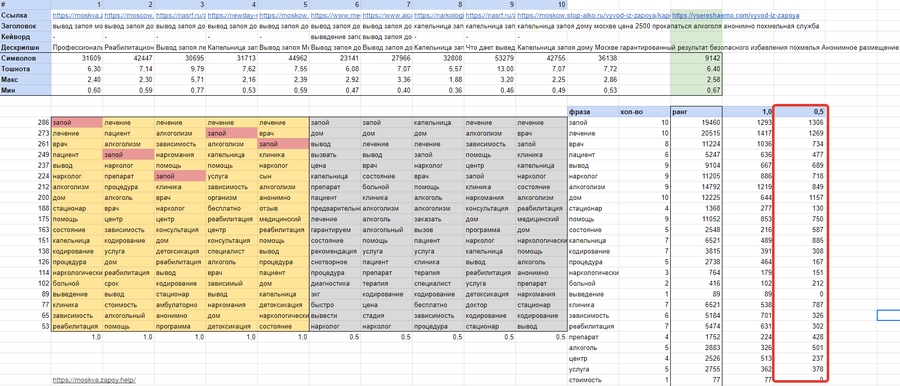
Удалите столбец «Значение», отфильтруйте столбец «Ранг» от более высокого к более низкому. Получение семантики LSI. Расставьте приоритеты слов и определите плотность ударов, которую вы хотите, чтобы они имели:
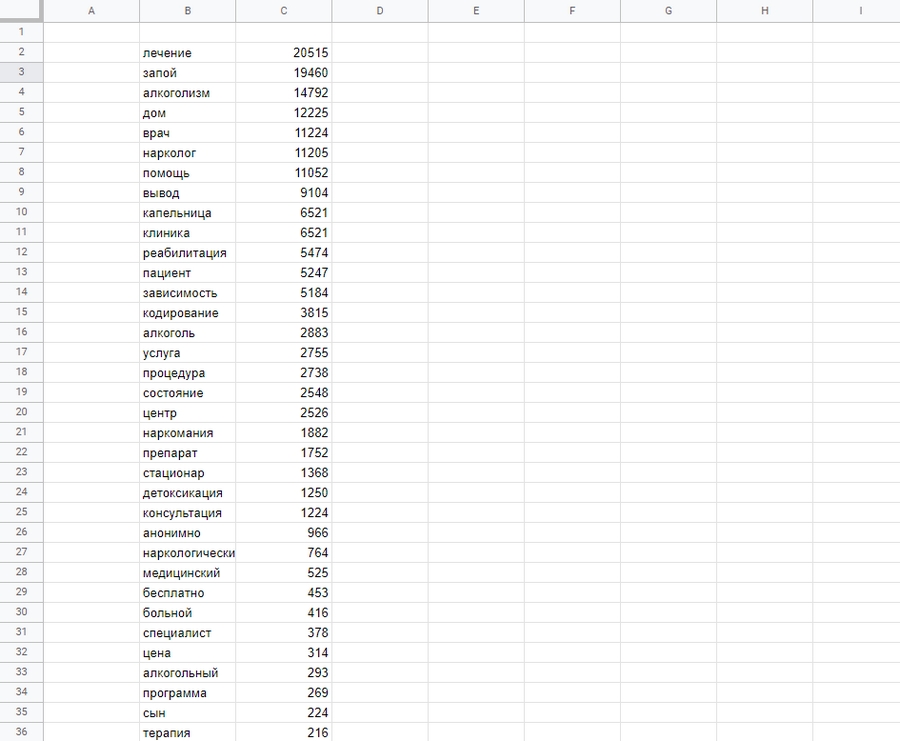
Шаг 5. Сравнение
Теперь у нас есть два пути.
- Ситуация первая — у нас нет страницы. Мы просто создаем целевую страницу на основе среднего количества символов, полученных фраз и плотности их встречаемости.
- Ситуация вторая — у нас уже есть страница. Проведите его анализ в сервисе SeoLik и введите фразы в колонку «Акцептор»:
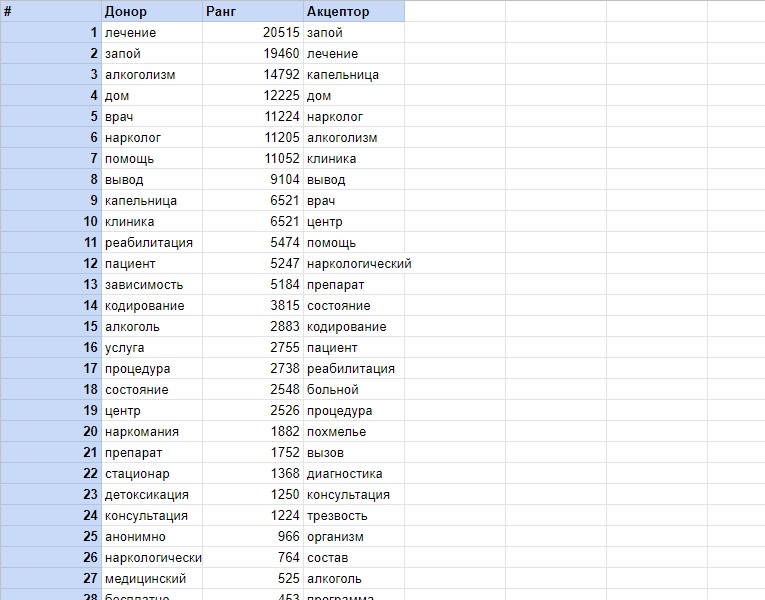
Шаг 6. Итог
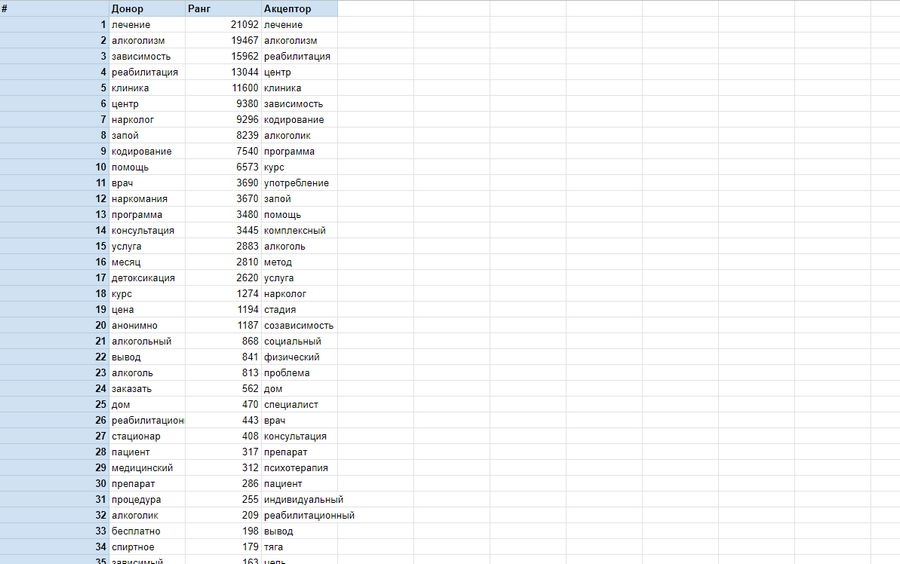
Последний шаг — сравнить два списка слов и «подтянуть» LSI-фразы, которые редко встречаются в теле нашей страницы, до необходимого уровня. Мы делаем это с помощью SeoLik (или p2pi), добавляя новые фразы или удаляя ненужные, пока столбцы «Донор» и «Акцептор» не станут равными.
Давайте сравним LSI-семантику донора с LSI-семантикой нашей страницы. Красным маркером мы отметим фразы, плотность которых следует увеличить, а зеленым — слова, которые следует удалить:
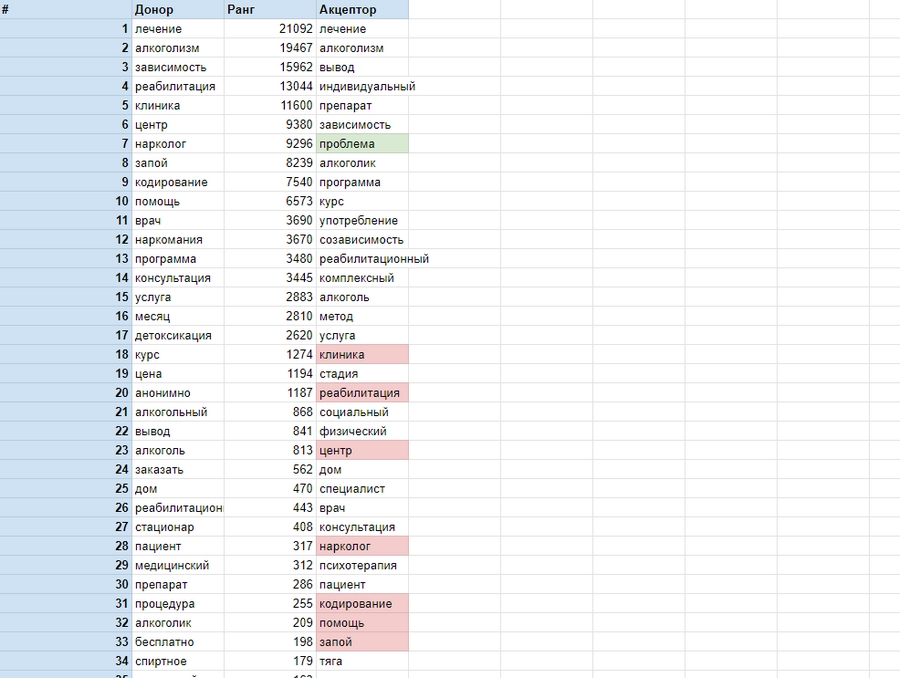
У нас есть список: «клиника», «реабилитация», «центр», «нарколог», «кодирование», «помощь», «передозировка». Мы включаем эти слова в текст страницы принятия. Повторно проанализируйте контент и получите результаты, которые покажут, что список и ранг LSI-фраз донора и реципиента более или менее одинаковы, в соответствии с требованиями.
В Google и Яндекс, социальные сети, рассылки, видеоплатформы, блоггеры



